Have you ever wondered how ChatGPT or Claude seems to "understand" you? To many, it feels like magic. To others, it's just "fancy autocomplete."
But if we peel back the layers and look at the actual engineering—the same stuff I've been studying in books by pioneers like Sebastian Raschka and Jay Alammar—we find something far more fascinating than magic.
Let's use the Richard Feynman technique—simplifying complex systems using everyday analogies—to understand how Large Language Models (LLMs) actually work.
1. Tokenization: The Lego Bricks of Language
Computers don't actually read words like "Elephant" or "Hydrogen." They only understand numbers. So, how do we bridge the gap?
Imagine you have a massive box of Legos. Every word in the human language is built from smaller, reusable blocks. Instead of having a single block for "unhappy," we might have a block for "un" and a block for "happy."
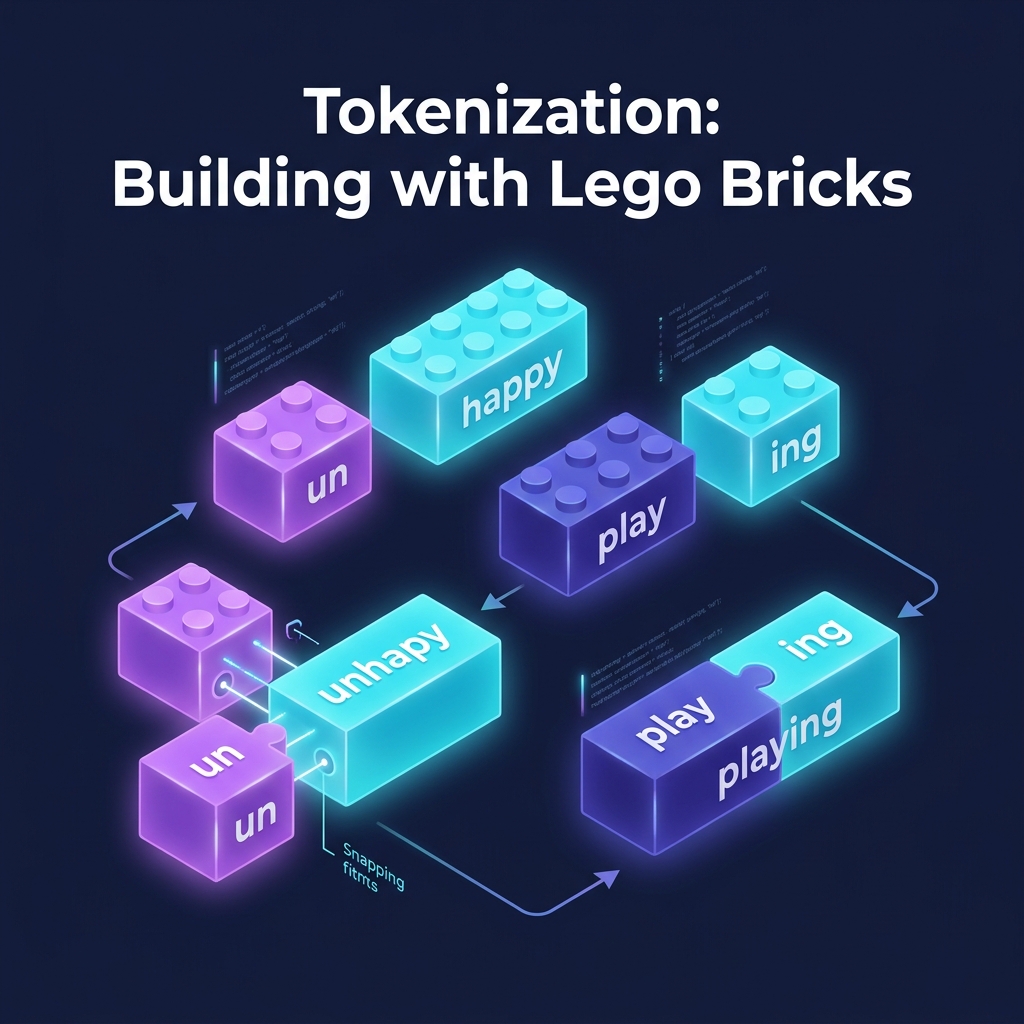 Tokenization is the process of breaking language into subword units. It allows the model to understand words it has never seen before by looking at their pieces.
Tokenization is the process of breaking language into subword units. It allows the model to understand words it has never seen before by looking at their pieces.
This is Tokenization. Most modern LLMs use a technique called Byte Pair Encoding (BPE). It breaks words down into the most efficient "bricks" possible. This is why an LLM can understand "Antidisestablishmentarianism"—it doesn't need to know the whole word; it just snaps together the pieces it already knows.
2. Attention: The Spotlight in the Library
Once the model has the Lego bricks, it needs to figure out what they mean in context. This is where the Transformer architecture comes in, and its secret weapon is called "Self-Attention."
Imagine you are in a pitch-black library with a single spotlight. You are trying to figure out what the word "it" refers to in the sentence: "The bank was closed because it was a holiday."
Does "it" refer to the bank? Or the holiday?
 The Attention mechanism acts like a spotlight, allowing the model to focus on the most relevant words in a sentence to determine context.
The Attention mechanism acts like a spotlight, allowing the model to focus on the most relevant words in a sentence to determine context.
The model uses its spotlight to scan the entire sentence at once (not left-to-right, like a human). It shines the light on "bank" and then on "holiday." It calculates which word has the strongest "relationship" to the word it's currently looking at. In this case, the spotlight lingers on "holiday" to explain the "why." This mathematical spotlight is what allows AI to "understand" nuance.
3. Training: The Self-Reading Student & The Teacher
How does the model learn where to shine the spotlight? It goes through two main phases of school.
Phase 1: Pre-training (The Self-Reading Student)
The model is given the entire internet. It plays a game of "Guess the Next Word" billions of times. It's like a student who reads 100,000 libraries but has no teacher. It learns the patterns of language, but it doesn't always learn how to be helpful. It might learn how to write a poem, but also how to argue or be rude.
Phase 2: RLHF (The Teacher's Feedback)
To turn that raw "pattern-matcher" into a helpful assistant, we use Reinforcement Learning from Human Feedback (RLHF).
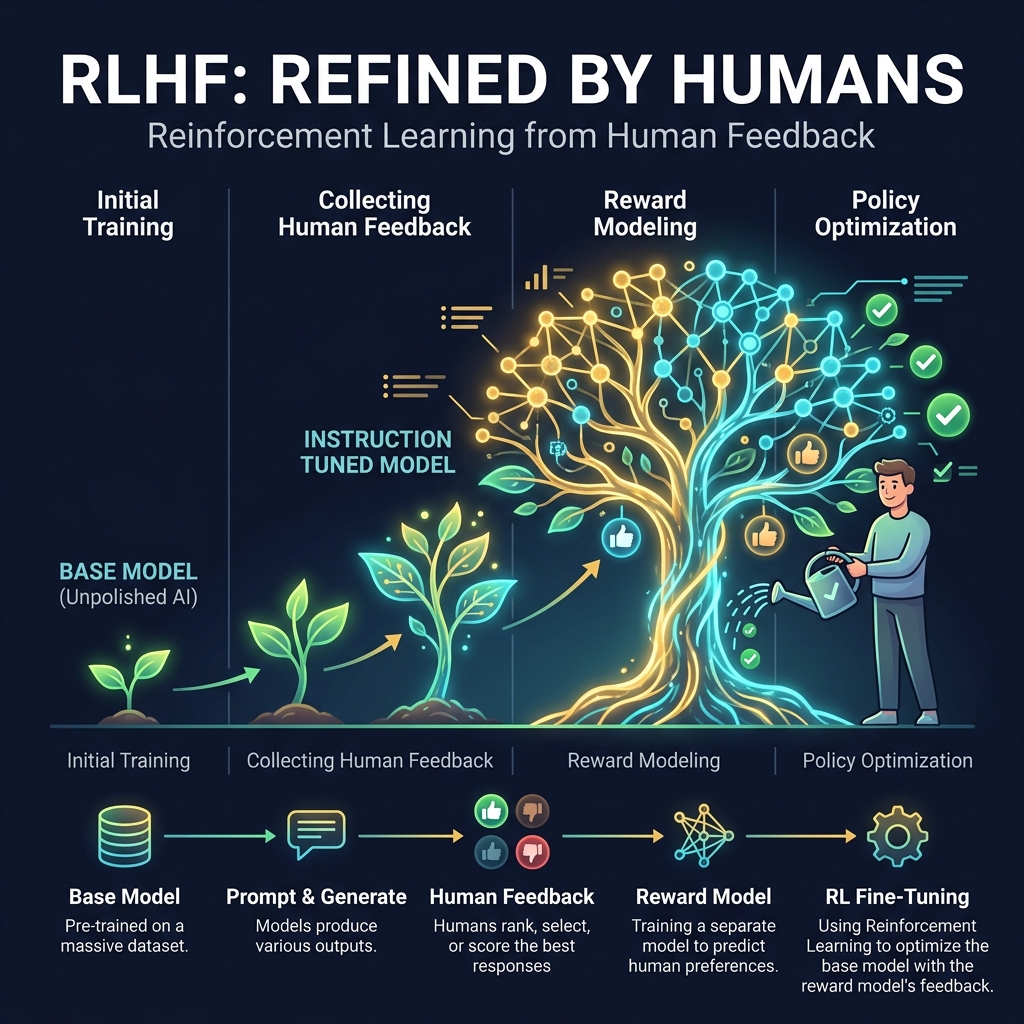 Human "teachers" review the model's outputs and give it a thumbs up or thumbs down. Over time, the model "grows" into a helpful and safe assistant.
Human "teachers" review the model's outputs and give it a thumbs up or thumbs down. Over time, the model "grows" into a helpful and safe assistant.
Think of it like watering a plant. We "water" the responses that are helpful, honest, and harmless, and we "prune" the ones that are confusing or dangerous. This is how we get from a chaotic text-guesser to a tool like ChatGPT.
4. RAG: The Open-Book Exam
One big problem with LLMs is that they have a "knowledge cutoff." They only know what they read during their initial school years. If you ask them about news from yesterday, they might guess (or "hallucinate").
To fix this, we use Retrieval Augmented Generation (RAG).
Imagine you are taking a history exam. You are a smart student with a great memory, but your teacher lets you use a library during the test. When you get a question you aren't 100% sure about, you don't guess—you walk to the shelf, grab the right book, and read the answer.
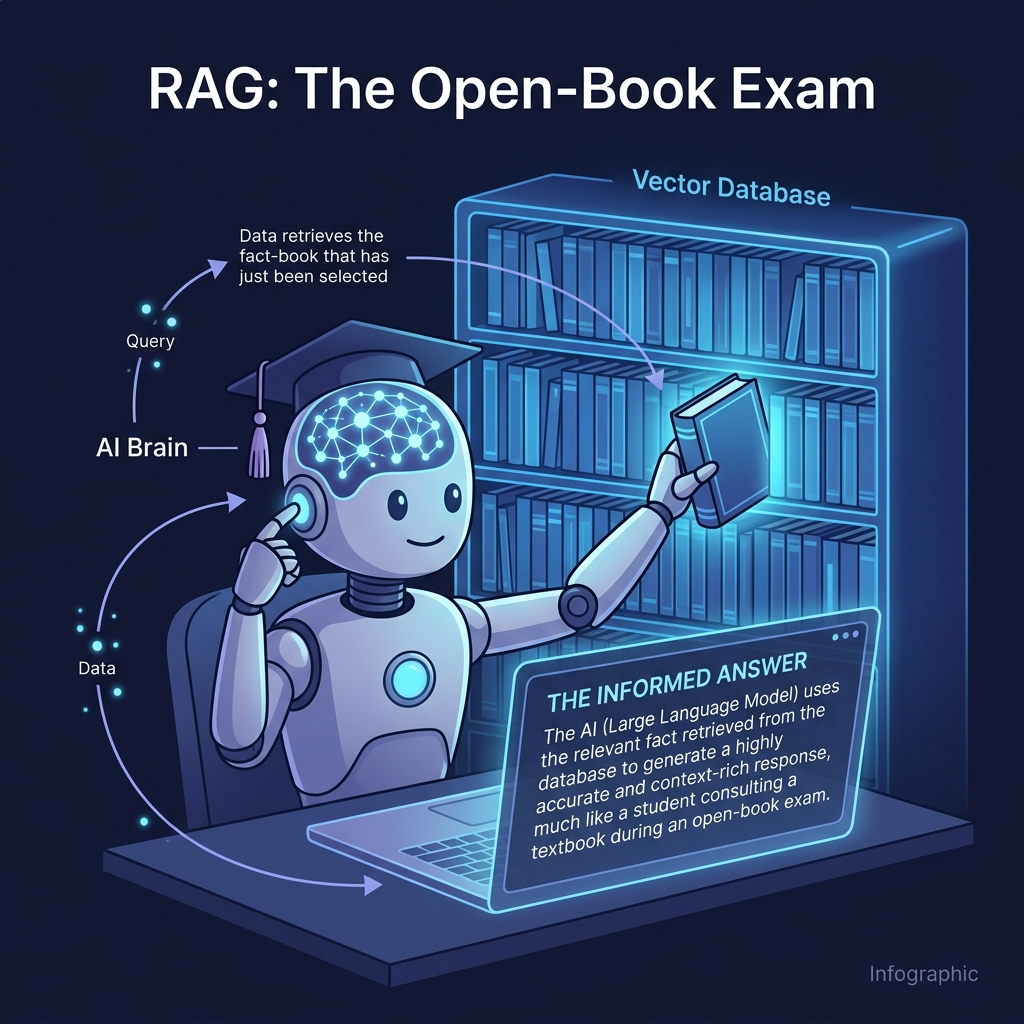 RAG allows the model to look up real-time, factual information from a secure "Vector Database" before answering, drastically reducing errors.
RAG allows the model to look up real-time, factual information from a secure "Vector Database" before answering, drastically reducing errors.
This is why modern AI "Agents" are so powerful. They don't just "know" things; they know how to find things.
References & Further Reading
This post was synthesized from the foundational concepts found in these exceptional engineering resources:
- Build a Large Language Model (From Scratch) by Sebastian Raschka. (Essential for understanding the Transformer architecture and Attention).
- LLM Engineer’s Handbook by Paul Iusztin & Maxime Labonne. (Great for RAG and Production patterns).
- Hands-On Large Language Models by Jay Alammar & Maarten Grootendorst. (The gold standard for visual explanations of NLP).
- Building LLMs for Production by Louis-François Bouchard. (Deep dive into reliability and evaluation).
The Verdict
LLMs aren't thinking beings—they are massive, incredibly sophisticated pattern-matching engines. They break language into bricks, use spotlights to find context, learn from human teachers, and pass open-book exams using databases.
By understanding these simple components, we can stop seeing AI as a "black box" and start seeing it for what it truly is: The most powerful language tool humanity has ever built.