You have almost certainly worked in a codebase that someone called a "microservices architecture" — and you have almost certainly thought: this is worse than a monolith.
You are not wrong. Most microservices implementations are worse than the monolith they replaced. The promise was independence, speed, and resilience. The delivery was a distributed mess of HTTP calls, a shared database with 12 owners, and log files scattered across 30 services.
Let me explain why this keeps happening — and what the engineers who get it right have in common. I am going to use the Richard Feynman technique: if I cannot explain it simply enough for a 12-year-old to understand the core idea, I do not understand it well enough myself.
The material here synthesizes insights from the most important books in the field: Sam Newman's Monolith to Microservices, Neal Ford and Mark Richards' Software Architecture: The Hard Parts, Martin Kleppmann's Designing Data-Intensive Applications, and Adam Bellemare's Building Event-Driven Microservices.
The Feynman Foundation: What is a Microservice, Really?
Before we talk about failure, let us make sure we agree on what the thing actually is.
Imagine a pizza restaurant. In a monolith, one person does everything: takes the order, makes the dough, adds the toppings, cooks the pizza, delivers it to the table, and processes the payment. Everything is in one place. Easy to understand. Easy to debug. If that one person gets sick, everything stops.
In a microservices architecture, you hire specialists. One person takes orders. One chef makes dough. One manages toppings. One operates the oven. One delivers. Each person can be replaced independently. You can hire two oven operators on a busy Saturday without hiring two of everyone else. That is independent scaling.
Sounds great, right?
Here is where the analogy breaks down — and where most real implementations go wrong. Those specialists still need to communicate. They need to coordinate orders. They need to share information about which pizzas are ready. And crucially, they need someone to be in charge of knowing the state of every order.
In software, that coordination problem is everything. Most teams solve the technical decomposition (splitting the code) but completely ignore the coordination problem (splitting the data and managing consistency). That is the root of every failure mode we will discuss.
Failure Mode 1: The Distributed Monolith
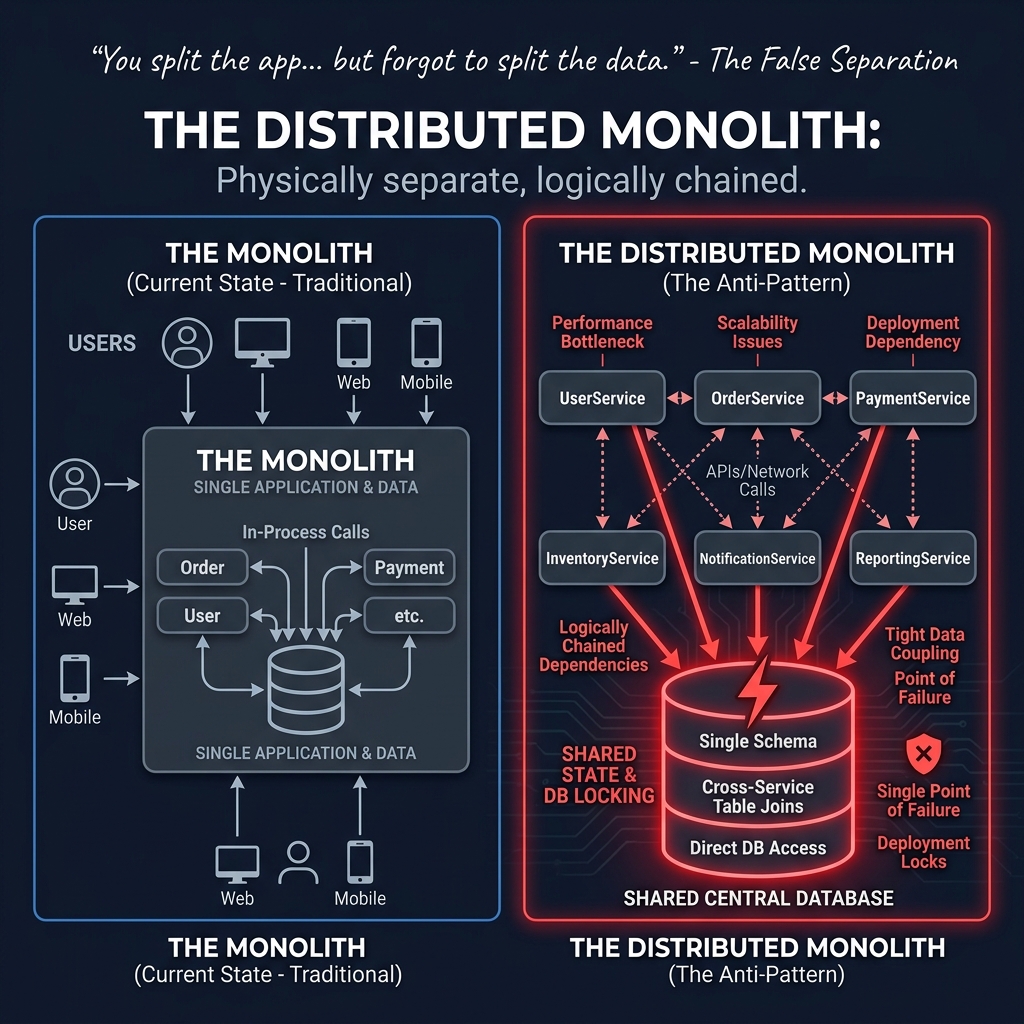 Six services, six teams — one shared database. This is not microservices. This is a monolith you made more expensive to operate.
Six services, six teams — one shared database. This is not microservices. This is a monolith you made more expensive to operate.
This is the single most common failure, and it is almost poetic in its irony.
A team splits their application into six services. The OrderService, UserService, PaymentService, and three others. They deploy them on separate pods. Different Git repositories. Different CI pipelines. It feels like microservices.
But all six services connect to the same PostgreSQL database.
Here is what Neal Ford and Mark Richards call the core problem in Software Architecture: The Hard Parts: the database is the real contract between services. When OrderService reads from the users table that UserService owns, you have created a silent coupling that no amount of separate deployments can fix. Change the schema in UserService, and you silently break OrderService. You cannot deploy independently. You are back to a monolith — but now you also have network calls instead of in-process calls.
The Feynman version: Imagine our pizza restaurant where all six specialists write their notes in the same shared notebook. If the order-taker changes the format of her entry, the chef misreads the toppings. You have not made the restaurant more efficient; you have made the notebook a single point of failure that everyone has to negotiate around.
The fix from Sam Newman is unambiguous: each service must own its data storage entirely. Cross-service data access flows through APIs or events. Never through a shared database. Period.
Failure Mode 2: Synchronous Everything — The Cascade of Death
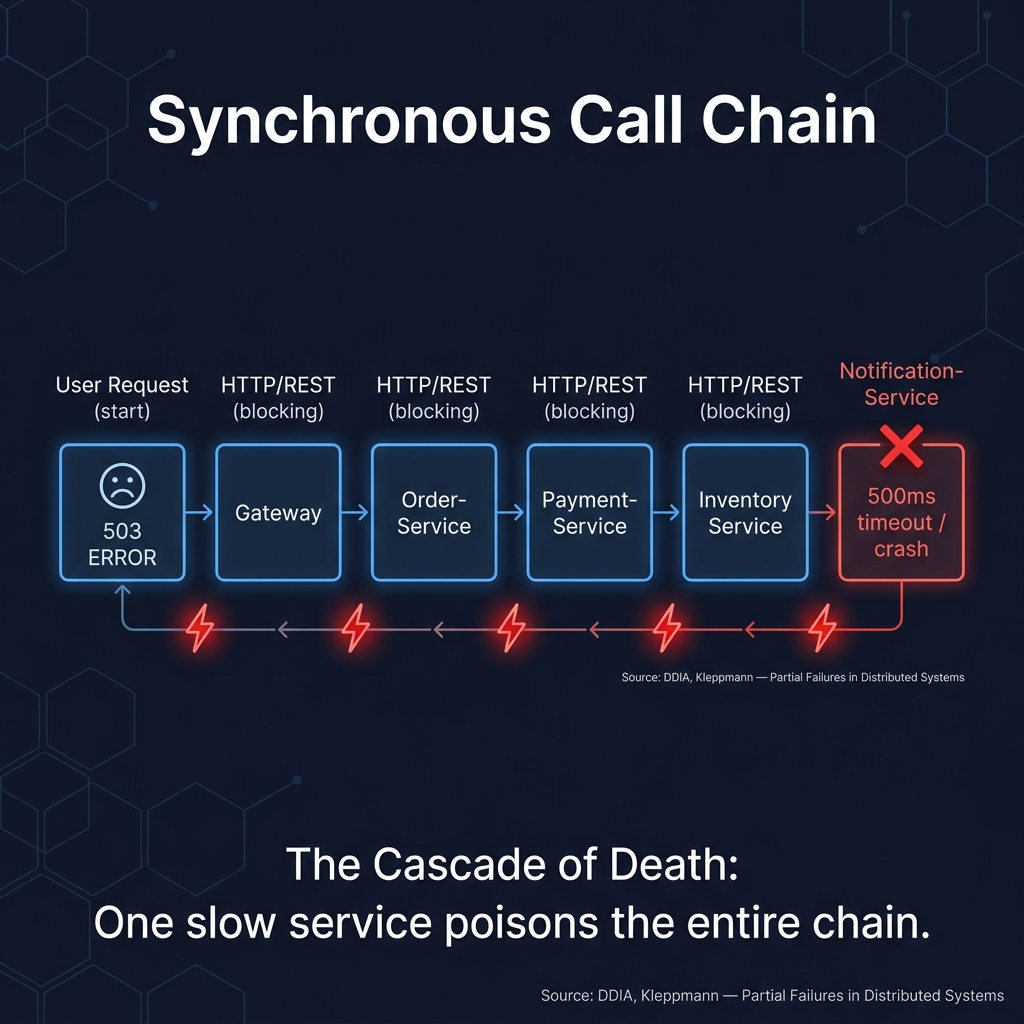 A chain of six synchronous HTTP calls. One slow service at the end turns into a 503 for the entire system.
A chain of six synchronous HTTP calls. One slow service at the end turns into a 503 for the entire system.
Here is a call pattern I find in nearly every struggling microservices codebase:
User Request
→ Gateway (REST)
→ OrderService (REST)
→ PaymentService (REST)
→ InventoryService (REST)
→ NotificationService (REST) ← 500ms timeout
Every call is synchronous. Every service waits for the next one. The chain is six hops long.
Martin Kleppmann dedicates a significant section of Designing Data-Intensive Applications to what he calls partial failures — a property unique to distributed systems and completely absent from monoliths. In a monolith, a function either succeeds or throws an exception. In a distributed system, a remote service can be slow, partially available, or return a stale response without any clear signal about which it is.
When NotificationService takes 500ms to respond, InventoryService is blocked waiting. That means PaymentService is blocked waiting for InventoryService. That means OrderService is blocked waiting for PaymentService. The user's request now takes 3 seconds just from waiting, before even adding the actual processing time.
The Feynman version: Imagine our pizza specialists forming a line where each one has to wait for the next before doing anything. The pizza-delivery specialist stands still until the oven operator is done. The oven operator stands still until the topping specialist finishes. One slow step blocks the entire kitchen.
The fix is to default to asynchronous, event-driven communication. If NotificationService is not in the critical path (does the user need the email confirmation before their order is confirmed?), publish an event to a message broker. NotificationService consumes it when it is ready. The user's order goes through in 50ms. The email arrives slightly later. The system as a whole is far more resilient.
Adam Bellemare's Building Event-Driven Microservices makes this case with industrial-scale examples: organisations that truly decouple their services through events stop having cascading failures. The blast radius of a single service failure is contained because nothing is waiting synchronously upstream.
Failure Mode 3: The Wrong Decomposition — Services Along Technical Layers
This failure mode is less dramatic but deeply debilitating. It happens when engineers decompose their system by technical concern rather than business capability.
I have seen this more times than I can count:
FrontendServiceowns all the React codeBackendServiceowns all the Java codeDatabaseServicemanages the data layer
Three "services." None of them independently deployable in any meaningful way. Adding a new business feature — say, a user preference panel — requires changing all three simultaneously, coordinating three deployments, and testing the integration between all three.
Mark Richards and Neal Ford describe this as a failure to understand bounded contexts, drawn from Domain-Driven Design. A bounded context is the natural language boundary of a domain. Inside it, every term has a single, unambiguous meaning. The Customer in the Billing context might be entirely different from the Customer in the Support context. Trying to merge them into a single CustomerService owned by three teams is a recipe for infinite coordination overhead.
The Feynman version: Imagine our restaurant decided to specialise by ingredient type rather than role. One specialist handles everything involving tomatoes. One handles everything involving cheese. One handles everything involving dough. To make a Margherita pizza, all three have to coordinate work at the same time. You have not made the kitchen more independent; you have forced three people to tightly collaborate on every single pizza.
The fix is to decompose around business capabilities: OrderManagement, CustomerNotifications, InventoryControl. Each one maps to a team, owns its own data, and can be deployed, scaled, and rewritten independently.
Failure Mode 4: Conway's Law Violated
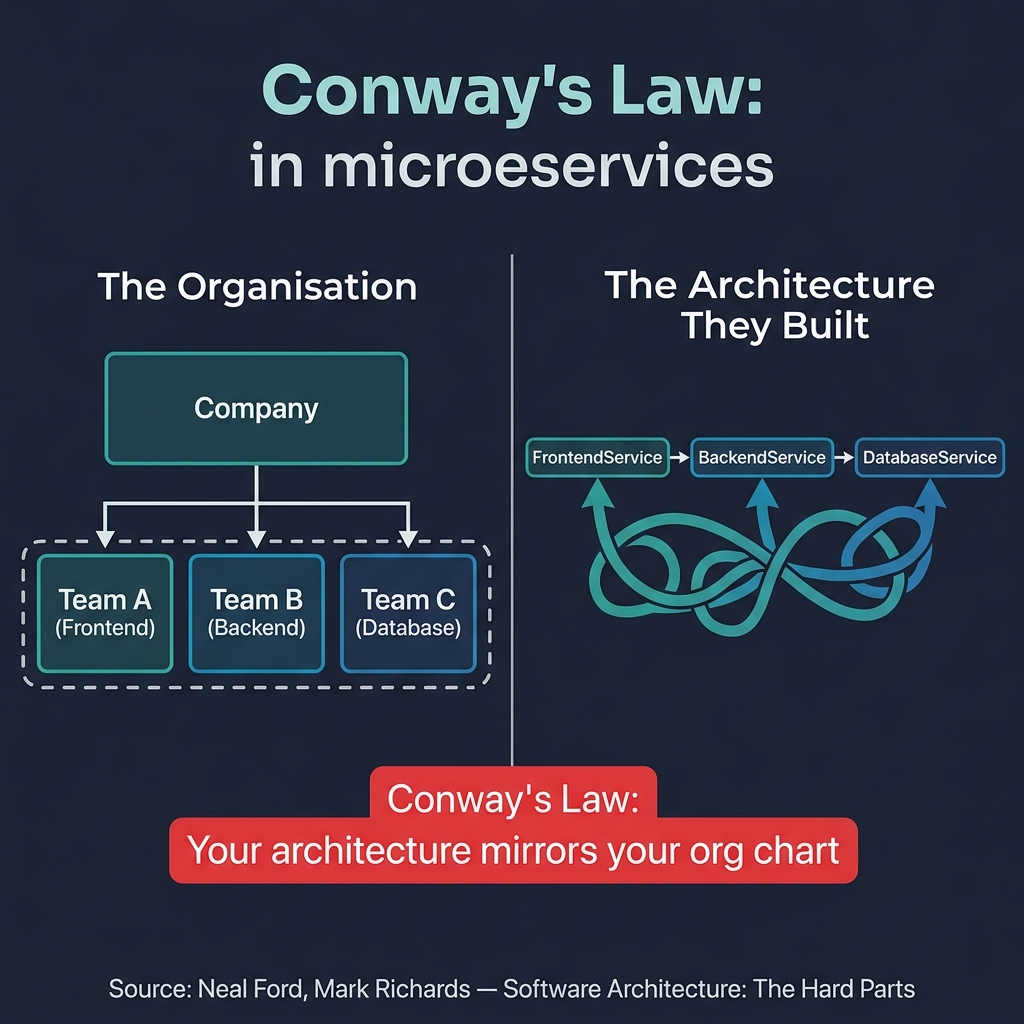 When the organisation is structured around technical layers, the architecture it produces will be a technically-layered distributed monolith.
When the organisation is structured around technical layers, the architecture it produces will be a technically-layered distributed monolith.
Melvin Conway observed in 1967 that "organisations which design systems are constrained to produce designs which are copies of the communication structures of those organisations." This was a sociological observation, not a technical one. But it is one of the most powerful lenses for understanding why microservices fail.
If your organisation has a separate Frontend Team, Backend Team, and DBA Team — your microservices will be a FrontendService, BackendService, and a shared database. Not because engineers made bad technical decisions, but because teams naturally build systems that mirror how they communicate.
Neal Ford and Mark Richards are explicit about this in Software Architecture: The Hard Parts: you cannot fix an architectural problem without fixing the organisational problem first. If the org chart forces two teams to own the same service, or one team to own five services that need to change together — no architectural pattern will save you.
The Feynman version: Imagine a kitchen where the chefs report to one manager, the waiters to another manager, and the kitchen cleaners to a third. Every decision about how to improve service requires all three managers to agree. The kitchen will reflect that friction — slow handoffs, unclear ownership, constant coordination overhead.
The fix — what Spotify famously called "squads" and what Sam Newman calls "stream-aligned teams" — is to structure your teams around business outcomes, not technical functions. Each team owns a full slice of the system from end to end.
Failure Mode 5: No Observability
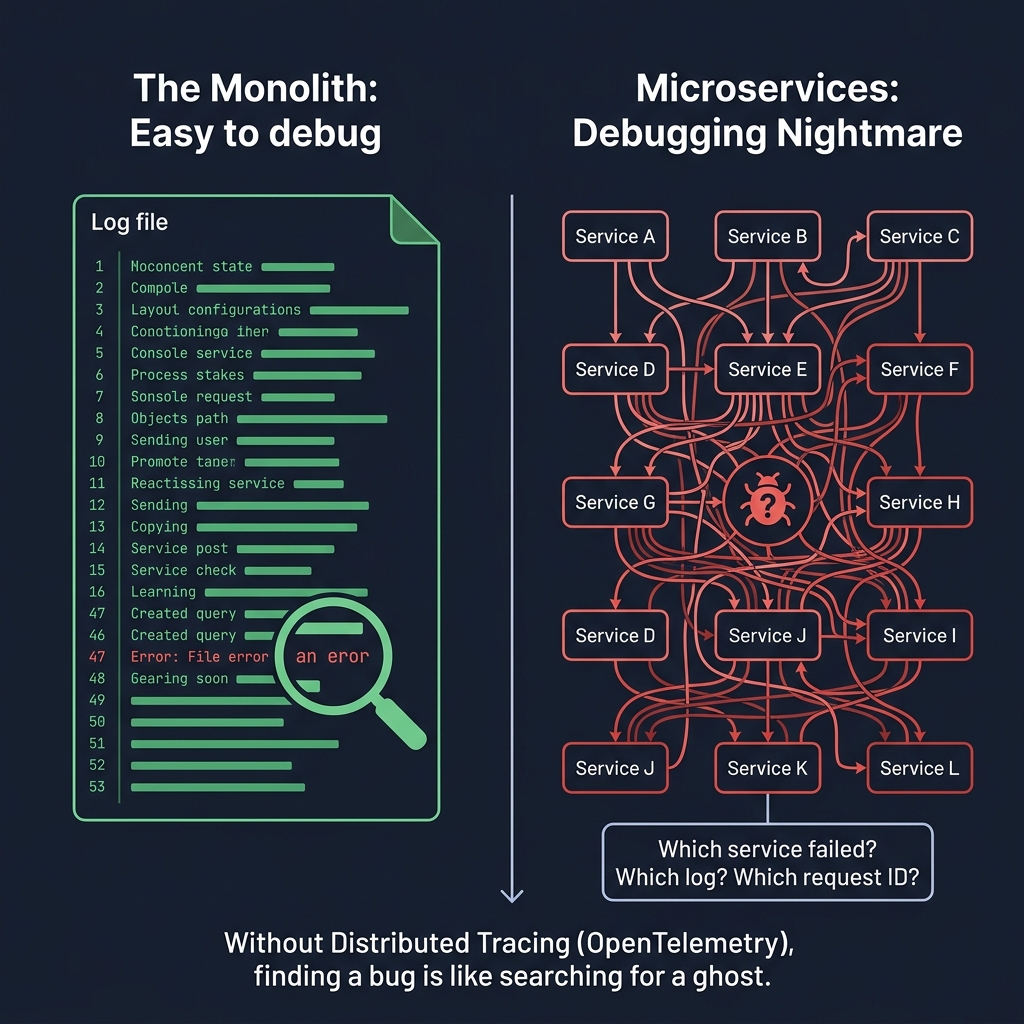 In a monolith, debugging is simple. In microservices without distributed tracing, a production bug is a ghost in a machine with 30 compartments.
In a monolith, debugging is simple. In microservices without distributed tracing, a production bug is a ghost in a machine with 30 compartments.
Here is a scenario that will be uncomfortably familiar to many engineers.
A user reports that their checkout process sometimes fails. In a monolith, you grep the log file. You find the exception. You fix it. Twenty minutes of work.
In a microservices system with 15 services and no distributed tracing: you look at the API Gateway logs. No error there. You check OrderService. No error. You check PaymentService. A warning, but it resolved. InventoryService? NotificationService? You are now in hour three, SSH-ing into different container logs, trying to find one failed request among millions.
This is the observability gap. Ian Gorton, in Foundations of Scalable Systems, describes distributed systems observability as a first-class architectural concern — not a post-launch operational task. Without three things — structured logging with correlated trace IDs, distributed tracing (OpenTelemetry), and meaningful SLIs and SLOs — debugging a microservices system at production scale is functionally impossible.
The Feynman version: Imagine 30 pilots flying in formation, and your dashboard in the control tower shows you... nothing. No altimeters. No fuel gauges. No radio. If any pilot deviates, you will not know until they crash.
The fix is non-negotiable: every service ships with structured JSON logs that carry a traceId on every log line. Every service emits distributed traces using OpenTelemetry. You never add a service without adding its observability layer first.
The Right Way: Extract, Don't Prematurly Decompose
 The decision to extract a service should be driven by demonstrated organisational or scale pain — not architectural ambition.
The decision to extract a service should be driven by demonstrated organisational or scale pain — not architectural ambition.
Sam Newman's Monolith to Microservices offers what I consider the most honest advice in the field: start with a monolith. Build your understanding of the domain first. Let the bounded contexts emerge from real usage. Then, when specific, demonstrable pain appears — a team that cannot deploy independently, a component that needs a different scaling profile — extract that component surgically.
The organisations I have studied that run microservices well share a set of traits that the failing ones do not:
| Trait | Failing Organisations | Successful Organisations | |---|---|---| | Starting point | Greenfield microservices | Well-understood monolith | | Decomposition driver | Tech blog posts | Demonstrated team friction | | Data ownership | Shared database | Strict per-service data isolation | | Communication style | Synchronous REST chains | Async events by default | | Observability | Logs in production | OpenTelemetry from day one | | Team structure | Functional (Frontend/Backend) | Stream-aligned (business domain) |
The key insight from Software Architecture: The Hard Parts is that every architectural decision is actually a trade-off analysis. Microservices give you independent deployability and scale — they cost you network complexity, data consistency challenges, and operational overhead. That trade is worth it when you have large teams with clear bounded contexts. It is catastrophically expensive when you do not.
The Uncomfortable Conclusion
Microservices are not a technology decision. They are an organisational design decision that happens to have technical implications.
If your organisational structure cannot support independent team ownership, if your engineers have not internalized eventual consistency, if your operations team cannot instrument distributed traces — microservices will not fix those problems. They will amplify them.
The engineers who laugh at microservices are usually the ones who were handed a distributed monolith and told it was a success. The engineers who swear by them are usually the ones who had the discipline to establish bounded contexts, event-driven communication, and observability before decomposing.
The architecture is never the problem. The maturity to execute it is.
References
This guide synthesizes principles and concepts from the following definitive texts on distributed systems and software architecture:
- Monolith to Microservices: Evolutionary Patterns to Transform Your Monolith by Sam Newman
- Software Architecture: The Hard Parts — Modern Trade-Off Analyses for Distributed Architectures by Neal Ford, Mark Richards, Pramod Sadalage & Zhamak Dehghani
- Designing Data-Intensive Applications by Martin Kleppmann
- Building Event-Driven Microservices: Leveraging Organizational Data at Scale by Adam Bellemare
- Foundations of Scalable Systems: Designing Distributed Architectures by Ian Gorton